3. Planejamento da pesquisa#
Além do levantamento bibliográfico e formação técnica mínima, como indicado nos capítulos 1 e 2, é importante definirmos, mesmo que de forma geral e preliminar, o planejamento específico voltado para documentação, organização, preservação e licenciamento da pesquisa.
Ou seja, é fundamental a elaboração de um plano de gerenciamento dos dados (DMP, do inglês Data Management Plan), que deve ser elaborado nessa primeira fase e atualizado ao longo do seu desenvolvimento.
O Open Science Framework (OSF) possui um conjunto de documentações de suporte específicas sobre o tema, e podem ser acessadas aqui.
Além do OSF, indicamos a leitura e avaliação do The Digital Documentation Process, que apresenta valiosas reflexões e diretrizes para catalogar e preservar objetos digitais.
Nessa pesquisa, optei por controlar todas as alterações, escolhas e decisões através do histórico criado com o Git, combinando com o GitHub para armazenamento e compartilhamento dos arquivos. Cada mudança e decisão foi registrada em mensagens de commit e armazenada no histórico do Git. Para saber mais, veja abaixo Sistema de controle de versões.
Também inseri o repositório completo no Zenodo, buscando garantir sua preservação, acesso e maior facilidade de citação e referência. O DOI do repositório é: 10.5281/zenodo.8397656.
Definição das estratégias de documentação#
A capacidade de preservar, recuperar, compartilhar e reutilizar os dados de uma pesquisa passa sobremaneira pela a forma como esses dados são documentados.
Segundo James Baker [Baker, 2021]:
O propósito da documentação é capturar o processo da criação de dados, as alterações ocorridas e o conhecimento tácito associado.
Na lição Preservar os seus dados de investigação, o autor faz um reflexão importante sobre as estratégias mais condizentes com o trabalho do historiador e lista estratégias e boas práticas para a documentação de pesquisas históricas.
Alguns pontos gerais são importantes de serem avaliados:
escrever explicitamente os critérios e os padrões adotados.
utilizar formatos de texto simples e multiplataforma, como
txt,mdecsv;incluir
README.mdouREADME.txtem cada diretório explicitando seu conteúdo;padronizar nomeação de diretórios e ficheiros;
pensar em formatos, padrões e convenções que sejam multiplataforma;
registar suas decisões;
produzir a documentação de forma continuada, durante todo o processo de pesquisa.
Sobre arquivos README, veja a documentação do GitHub. Aqui um exemplo de README explicando o conteúdo de um diretório: README.md.
Imaginemos aqui um exemplo de estrutura de armazenamento de dados de um projeto de pesquisa.
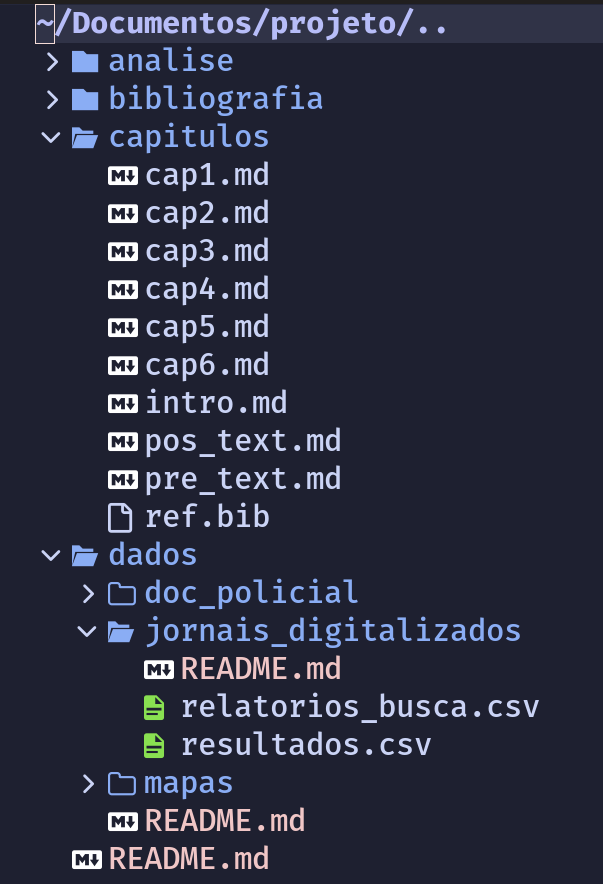
Fig. 12 Exemplo simples de estrutura de ficheiros e diretórios.#
Na imagem a seguir podemos ver a estrutura de diretórios e ficheiros utilizada nessa pesquisa:
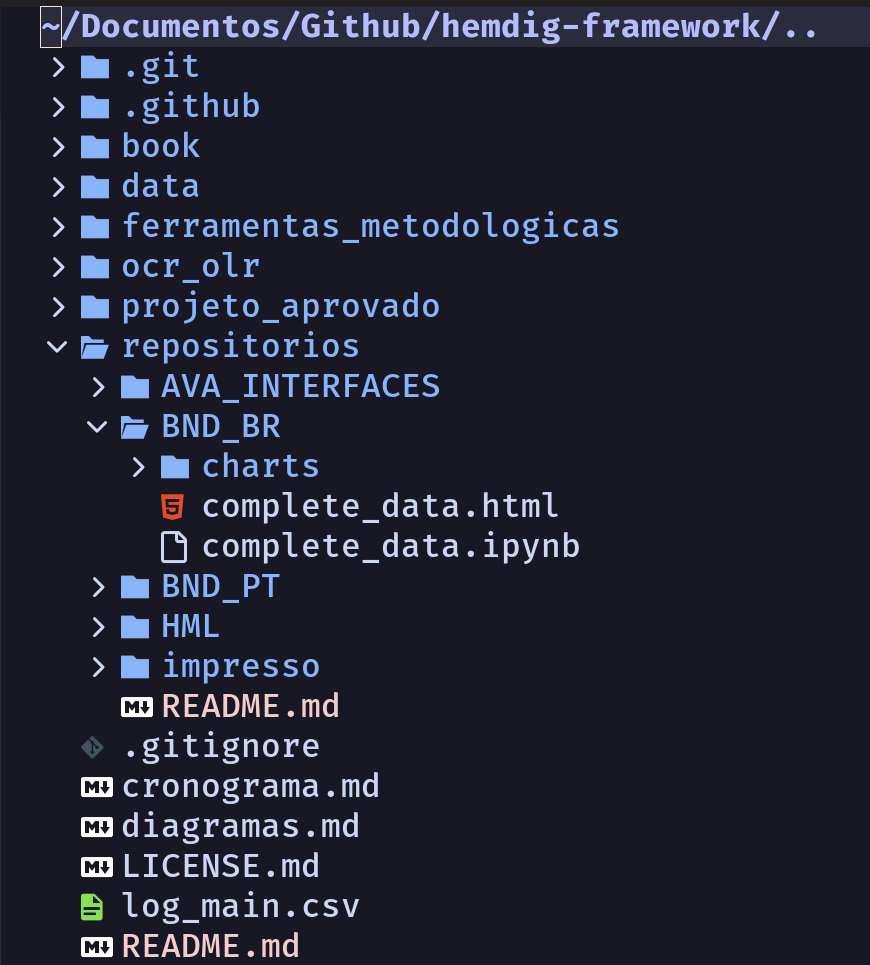
Fig. 13 Estrutura de diretórios e ficheiros do repositório do HEMDIG(pt)#
Sistema de controle de versões#
Uma das estratégias mais robustas de documentação e organização da pesquisa é a utilização de um sistema de controle de versões, como o Git. Apesar de possuírem uma curva de aprendizado mais acentuada, os SCVs são ferramentas poderosas para o controle das alterações e o registro das decisões e escolhas ao longo do processo de pesquisa.
Em artigo recente publicado no Programming Historian, intitulado Git como ferramenta metodológica em projetos de História (parte 1), explico o que é um SCV [Brasil, 2023]:
Um SCV consiste em um sistema que registra as mudanças de um ficheiro ou conjunto de ficheiros ao longo do tempo, cada uma dessas mudanças é acompanhada de um conjunto de metadados (ou seja, informações sobre os dados), e te permite recuperar tanto esses dados quanto o estado em que se encontrava o seu projeto há época.
É como se você possuísse uma máquina do tempo capaz de te levar de volta a qualquer ponto da história de mudanças da sua pesquisa.
E em seguida, resumo o Git:
O Git é um SCVs de arquitetura distribuída. Foi criado em 2005 por Linus Torvalds1 e atualmente é o mais popular do mundo (em inglês). Ele é um software livre e gratuito, com uma grande comunidade de usuários e documentação extensa e detalhada. O Git “gerencia a evolução de um conjunto de ficheiros - chamado repositório ou repo - de uma forma consciente e altamente estruturada” (Bryan, 2018, p. 2, tradução minha). Todas as mudanças são registradas (commits) assim como um conjunto de metadados para cada commit: identificação única, autoria, mensagem e data. Esses mecanismos e informações permitem a compreensão geral da história do desenvolvimento de um projeto (Kim et al., 2021, p. 657).
O Git compreende seus dados como “uma série de snapshots de um sistema de arquivos em miniatura”, ou seja, toda vez que você submete uma alteração ao repositório, o “Git basicamente tira uma fotografia de como todos os seus ficheiros são naquele momento e armazena uma referência para aquele snapshot” (Chacon e Straub, 2014, p. 15). Se um ficheiro não foi modificado, o Git não o armazenará novamente, apenas cria um link atualizado para ele, o que o torna mais leve e rápido. Essas características garantem a integridade do Git, visto que é impossível alterar o conteúdo de qualquer ficheiro ou diretório sem o Git saber (Chacon e Straub, 2014, p. 15). Praticamente todas essas operações acontecem localmente, minimizando problemas relativos à conexão com servidores, violação de dados e segurança.
Ao longo do artigo, apresento as principais funcionalidades do Git e como utilizá-las, assim como apresento boas práticas de documentação através das mensagens de commit. E concluo:
O uso consciente e sistemático do Git, apesar de sua curva de aprendizado mais acentuada, permite que pesquisadores e equipes possam trabalhar de forma segura e controlada, integrando ao processo de pesquisa/escrita os procedimentos metodológicos de documentação e registro de metadados e decisões tomadas. Ao mesmo tempo, garante a criação de uma linha do tempo de todo o processo, permitindo a recuperação das informações e restauração de ficheiros.
Entendo que com o Git no cotidiano de uma pesquisa, ganhamos tempo e tranquilidade para documentar, preservar e recuperar informações, assim como apresentar de forma transparente todas as nossas decisões e escolhas a qualquer momento.
Definição das estratégias de organização#
Definir as estruturas de organização dos dados (em diretórios, ficheiros, etc.) é uma tarefa importante, e está diretamente ligada ao processo de documentação. Alguns pontos podem ajudar a iniciar tal reflexão:
Pensar estrutura de diretórios padronizada;
Nomear ficheiros de forma padronizada;
Criar padrão de realização de backups;
Explicitar o uso de serviços de nuvem e sincronização de dados.
Avaliar ferramentas de organização de dados e referências bibliográficas.
Incluir decisões de organização na documentação.
FAIR#
Uma outra filosofia que pode nos ajudar a pensar a organização dos dados é o FAIR. Do inglês Findability, Accessibility, Interoperability, and Reuse de dados digitais, o FAIR nos indica princípios que devem guiar a nossa elaboração de estratégias de organização e documentação de dados.
Listo abaixo, de forma resumida, os princípios FAIR (que estão disponíveis aqui):
Findable
F1. (Meta)data are assigned a globally unique and persistent identifier
F2. Data are described with rich metadata (defined by R1 below)
F3. Metadata clearly and explicitly include the identifier of the data they describe
F4. (Meta)data are registered or indexed in a searchable resource
Accessible
A1. (Meta)data are retrievable by their identifier using a standardised communications protocol
A1.1 The protocol is open, free, and universally implementable
A1.2 The protocol allows for an authentication and authorisation procedure, where necessary
A2. Metadata are accessible, even when the data are no longer available
Interoperable
I1. (Meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (Meta)data use vocabularies that follow FAIR principles
I3. (Meta)data include qualified references to other (meta)data
Reusable
R1. (Meta)data are richly described with a plurality of accurate and relevant attributes
R1.1. (Meta)data are released with a clear and accessible data usage license
R1.2. (Meta)data are associated with detailed provenance
R1.3. (Meta)data meet domain-relevant community standards
Zotero#
Como já indicamos no capitulo 1, o Zotero é um software livre e gratuito, que permite a organização de referências bibliográficas. Desenvolvido por uma equipe liderada por historiadores/as, o Zotero é uma ferramenta já consolidada com milhares de usuários, possui muitos tutoriais e plugins para ampliar seus recursos.
É possível inserir dados de muitas formas no Zotero, desde manualmente, até a importação em massa a partir de plataformas on-line e a partir de extensões em navegadores. Além disso, é possível integrá-lo ao seu editor de texto e ainda exportar dados para outros formatos, como CSV,BIB, RIS, etc.
Assim, indicamos sua utilização para o gerenciamento daquilo que historiadores chamam de fontes secundárias, como livros, artigos, etc. Apesar de também ser possível utilizá-lo para armazenar e organizar fontes primárias, como documentos de arquivo, fotografias, etc., indicamos o uso do Tropy, que será apresentado a seguir, por se tratar de uma ferramenta desenvolvida especificamente para esse fim.
Tropy#
Assim como o Zotero, o Tropy é um software livre e gratuito, que permite a organização de fotografias de documentos de arquivo, com a vantagem de permitir a anotação de metadados e a exportação de dados para outros formatos, como CSV e JSON e aceitar a importação de dados em uma ampla variedade de formatos.
Indicamos sua utilização como uma ferramenta de organização e documentação bastante prática, fácil de utilizar e desenvolvida pela mesma organização que desenvolveu o Zotero.
Para saber mais sobre o Tropy, acesse: https://tropy.org/
Abaixo, podemos ver uma oficina ministrada por Anita Lucchesi, apresentando desde a instalação até a utilização do programa.
Definição da licença de uso#
Uma prática importante, mas ainda pouco usual no campo das Humanidades é a definição de uma licença de uso para os dados gerados durante a pesquisa.
Como parte significativa de nossas pesquisas utiliza dados públicos e é financiada também por recursos públicos, é importante escolhermos licenças que permitam o acesso, mas também a reutilização dos dados por outros pesquisadores.
Obviamente precisamos levar me conta questões éticas e legais para a definição da licença, mas é importante que a escolha seja feita de forma consciente e documentada.
Para dados e materiais que não sejam programas de computador, é recomendado a utilização de licenças Creative Commons, que permitem a reutilização dos dados, desde que citada a fonte e a licença original.
No site Choose a License é possível encontrar uma lista e indicações de quais licenças mais apropriadas para cada tipo de material e pesquisa.
Definição dos repositórios#
Também é importante registrar as escolhas e decisões que levaram à seleção dos acervos utilizados na pesquisa. Explicitar não apenas as listas de fontes encontradas, mas todo o processo de busca, citando e listando inclusive os acervos descartados após abordagem inicial, etc.
É importante ressaltar que parte significativa dos apontamentos feitos nessa seção não são exclusividade para pesquisas utilizando dados digitais. Pelo contrário, o cuidado e rigor metodológico na pesquisa histórica é um elemento formador da disciplina. Necessitamos, sem dúvida, incorporar outros elementos e ferramentas nesse processo, contudo, o mais importante é reforçar as práticas básicas de crítica e rigor metodológico que são a base de nossa disciplina.
Ao utilizarmos acervos, ferramentas e métodos digitais, muitas vezes ficamos entre dois polos arriscados: de um lado, apenas emulamos práticas analógicas sobre dados digitais, deixando de refletir e aprofundar questões específicas, quase que naturalizando sua presença na prática da pesquisa, escrita e ensino; de outro lado, romantizamos as “novas tecnologias” e deixamos para trás as práticas e reflexões teórico-metodológicas que são distintivas da História.
Aqui, busca um caminho de aproximação, justamente pensando na importância de adquirirmos conhecimentos técnicos atualizados e submeter-los à análise crítica e reflexão teórica.
Referências#
James Baker. Preservar os seus dados de investigação. The Programming Historian em português, January 2021. URL: https://programminghistorian.org/pt/licoes/preservar-os-seus-dados-de-investigacao (visited on 2021-05-12), doi:10.46430/phpt0001.
Eric Brasil. Git como ferramenta metodológica em projetos de História (parte 1). 2023. doi:https://doi.org/10.46430/phpt0045.